L versus P and The Tree Evaluation Problem
Update: An extended abstract I wrote that outlines the Tree Evaluation Problem and summarizes some of the results in my longer write-up was published in the Review of Undergraduate Computer Science. Check it out on the RUCS website.
In a broad sense, one of the major themes in complexity theory research involves trying to understand the relationships between different complexity classes. P versus NP is the most famous example, but there are also many other interesting questions that one can ask about the relationships between complexity classes, many of which remain unanswered after years of work. For now, we are interested in the classes L, NL, and P.
Briefly, L is the class of all problems that can be solved by a Turing machine using a number of bits of memory that is logarithmic in the size of the input. An example of a problem in L is that of determining whether there is a path between two vertices in an undirected graph. NL is the class that we get by using the same definition, but with a nondeterministic Turing machine. P, probably the most well-known complexity class, contains all problems that are solvable in polynomial time.
If you’ve studied a bit of complexity theory, then you probably know that L is contained in P. However it’s unknown whether the reverse is true: Can any problem that is solvable in polynomial time also be solved in logspace?
In an attempt to answer this question, Steve Cook and others introduced the tree evaluation problem. This is a problem that is known to be solvable in polynomial time, however it is conjectured that a logarithmic number of bits of memory is not sufficient to solve this problem.
This past semester, I’ve had the privilege of working on a research project supervised by Steve Cook and David Liu, where we worked on methods of attacking lower bounds for the tree evaluation problem for height 4 trees. In this post, I won’t focus too much on technical details, but I’ll give an outline of the general problem, and why it’s interesting.
If you are interested in more details, you can check out the original STOC paper (also available on arXiv) introducing the tree evaluation problem, as well as my own final writeup for this particular research project, which serves as a basis for most of the content of this post.
The Tree Evaluation Problem
Suppose that we are given a perfect binary tree of height \(h\), with a bit of extra information at each node. At every internal node \(v_i\), we are given a function \(f_i:[k] \times [k] \to [k]\) mapping a pair of numbers from \(1\) to \(k\) to another number in that range, and at every leaf we are given a number from \(1\) to \(k\). Suppose that the numbers are “fed upwards” from the leaves up to the root, so that each internal node gets the value of its function when applied to the values of its two children. The goal of the (binary) tree evaluation problem, denoted \(FT_2^h(k)\), is to find the value of the root.
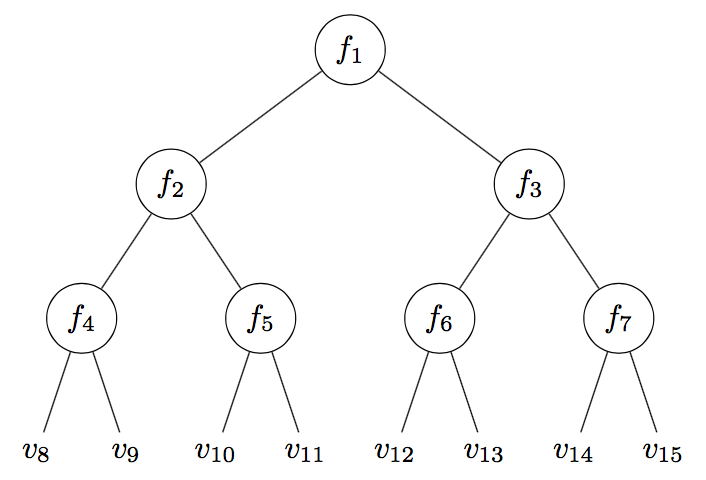
Illustration of an input to the height-4 binary TEP.
It’s easy to solve \(FT_2^h(k)\) in polynomial time, which you can check for yourself. However so far nobody has come up with an algorithm to solve this problem in logspace.
Although what we care about is the amount of memory required to solve the TEP using a Turing machine, it often seems easier to instead prove lower bounds for a more concrete model of computation: In this case, we wish to prove lower bounds on the number of states required by a branching program solving the TEP. It turns out that branching program size is closely connected to Turing machine space. In order to prove that L \(\neq\) P, it would suffice to show that any branching program solving \(FT_d^h(k)\) requires \(\Omega(k^{r(h)})\) states for some unbounded function \(r(k)\), as \(k\) increases.
I’ll probably write more about branching programs and some results about them in a later post, but for now, if you’re not familiar with them, you can think of a branching program as being like a decision tree, consisting of nodes that represent queries made by the program (in this case, to a leaf value \(v_i\) or a function value \(f_i(a,b)\)). However, in a branching program, the underlying graph is allowed to be an arbitrary DAG, rather than a tree. Generally, we can prove Turing machine space lower bounds by proving branching program size lower bounds for solving a given problem.
Lower Bounds for Tree Evaluation
For general branching programs, so far we don’t have any branching program size lower bounds that are known to be optimal for solving the TEP for trees of arbitrary height; otherwise we would have proved that L \(\neq\) P! The standard black pebbling algorithm (which runs in polynomial time but not in logspace) is known to be optimal for trees of height 3, however so far we have been unable to extend our lower bounds to trees of height 4.
In general, it’s typically a very difficult feat to prove lower bounds for general models of computation. So instead, we can consider various restricted models, in which it is easier to prove lower bounds, and hope that it may be possible to extend such results to more general models. For example, James Cook and Siu Man Chan showed that solving the TEP using a read-once branching program requires at least \(\Omega(k^h)\) states, using useful facts about certain polynomials over finite fields.
For the case of height 4 trees, we have also proved \(\Omega(k^4)\) state lower bounds for a number of different restricted models, such as branching programs in which the root is queried last on any computation, or when all root queries are made on the correct values of its left and right children. Proofs of these lower bounds tend to follow a fairly general structure. First, we can show that some states in the branching program must “know” certain information about the input, often by using a path switching argument to show that if the branching program didn’t know something about the input, then we could force it to make a mistake by adversarially changing the input. We might refer to such states that know a lot of information critical states.
Once we’ve done the previous step, we have a couple of options. If we’re lucky, we can convert the branching program to one that solves a related problem for which we already have an existing lower bound, and apply that to the current problem. Alternatively, we may use various techniques to show that only a small fraction of all inputs can reach a given critical state, and therefore it must follow that the branching program must contain a large number of critical states.
One thing that’s interesting to note is that it seems like it’s easier to prove lower bounds for branching programs that have very tight restrictions on where and how the root function can be queried. Intuitively, it shouldn’t matter whether a branching program queries the root functions at values that might be incorrect, however we have so far been unable to prove this. This is because it becomes a lot more difficult to reason about the behaviour of a branching program when it is allowed to mix function and leaf queries arbitrarily.
To sidestep this issue, rather than considering the functions on internal nodes as being part of the input, we can instead fix them to be particular functions, and instead study branching programs that only make leaf queries. For example, the lower bound that I mentioned above for read-once branching programs is done by fixing the internal functions to be a particular polynomial over the finite field \(GF(k)\). It turns out that this method actually works, because a lower bound of \(\Omega(k^{h-2})\) leaf queries needed to solve the TEP for trees of height \(h - 1\) would actually apply an \(\Omega(k^h)\) state lower bound for solving the TEP for trees of height \(h\).
Conclusion
I hope that I’ve done a good enough job of giving a high-level overview of the tree evaluation problem, and why it’s interesting. Branching programs are a particularly interesting model of computation, even though they don’t seem to get a whole lot of attention, from what I can see. I’ll likely write a post at some point in the future going into more detail about branching programs, and perhaps some interesting results concerning branching programs.